AI visibility as a tool category started taking shape in 2024. The first products solved a specific problem: show whether AI mentions your brand in responses to user queries. Yes or no. Weekly mention percentage. Share of voice relative to competitors.
That mattered. For the first time, marketing teams got some visibility into a channel that had been a complete black box. First-generation tools proved that AI visibility can be measured and that it matters for business.
But as AI search became a real channel for purchase decisions, the limitations of mention monitoring became obvious. Knowing that you were mentioned is useful. Knowing your exact position, why you’re there, and what specifically to fix is a different level of problem entirely.
What first-gen does well and where it stops
First-generation tools do their job well: send a query to a model, parse the response, record whether your brand was mentioned. Aggregate data into a visibility score or share of voice. Set up alerts: if your brand drops out of responses, you’ll know.
For many use cases, that’s enough. If you need a stakeholder report on your brand’s presence in AI responses, mention monitoring covers it. If you need to understand broad trends - whether your presence is growing or declining - it works for that too.
The problem comes when a marketing team tries to move from observation to action.
“Our visibility score is 47%.” Is that good or bad? Without position context, it’s impossible to answer. A brand with 47% could be consistently in the top 3 recommendations for half its queries. Or it could be at position #8-9 almost everywhere but technically “mentioned.” Two completely different business realities, same metric.
“Our share of voice dropped 12%.” Why? What specifically changed? Which source or which phrasing influenced the model’s decision? Monitoring captures the fact that something changed, but it doesn’t provide diagnostics.
The CMO walks into the CEO’s office with a chart. The CEO asks “what are we doing about it?” And the conversation stalls, because the data gives observation but not a plan.
What “second generation” means
Second-generation tools solve a different problem. Not “was your brand mentioned,” but “what position are you in, why are you there, and what needs to change to move up.”
The difference is architectural, not cosmetic.
Positioning instead of a binary metric
When a user asks AI “what’s the best CRM for a 10-person startup,” the model generates a response with an implicit hierarchy. The first brand gets maximum context, detailed description, favorable framing. By position five or six, brands get a single sentence. By position eight, they’re filler.
Users distribute attention accordingly: the overwhelming majority focuses on the first three recommendations. Position #2 and position #9 produce the same visibility score in first-gen tools. In practice, it’s the difference between conversion and zero.
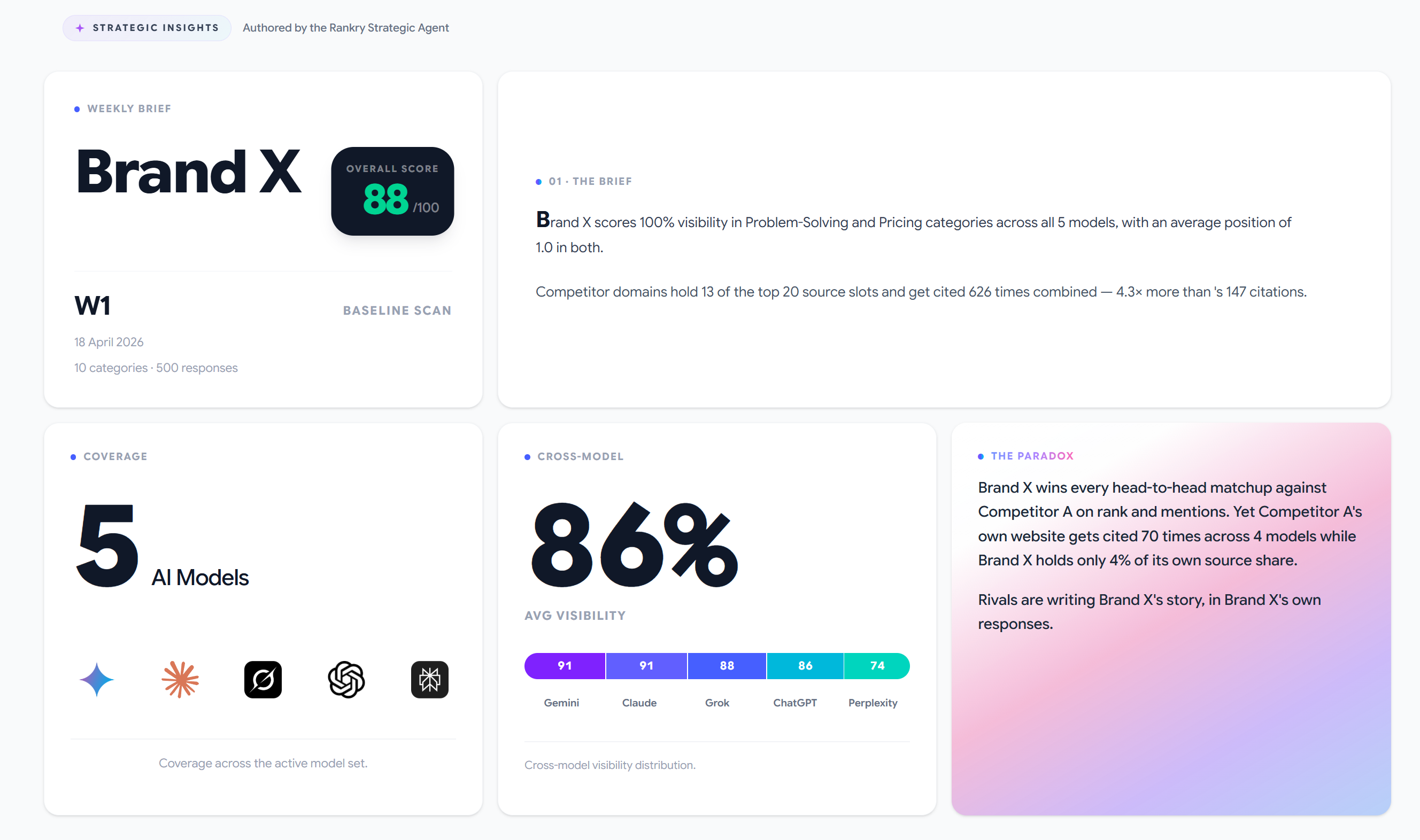
Second generation measures specific position in each model for each query. Not “mentioned in 47% of responses,” but “#3 in ChatGPT, #7 in Gemini, #2 in Perplexity.” That’s data you can work with.
Reasoning: why the model chose what it chose
A standard AI response is generated in default mode. The model isn’t required to rank and isn’t required to explain its choices. You’re working with a byproduct of text generation.
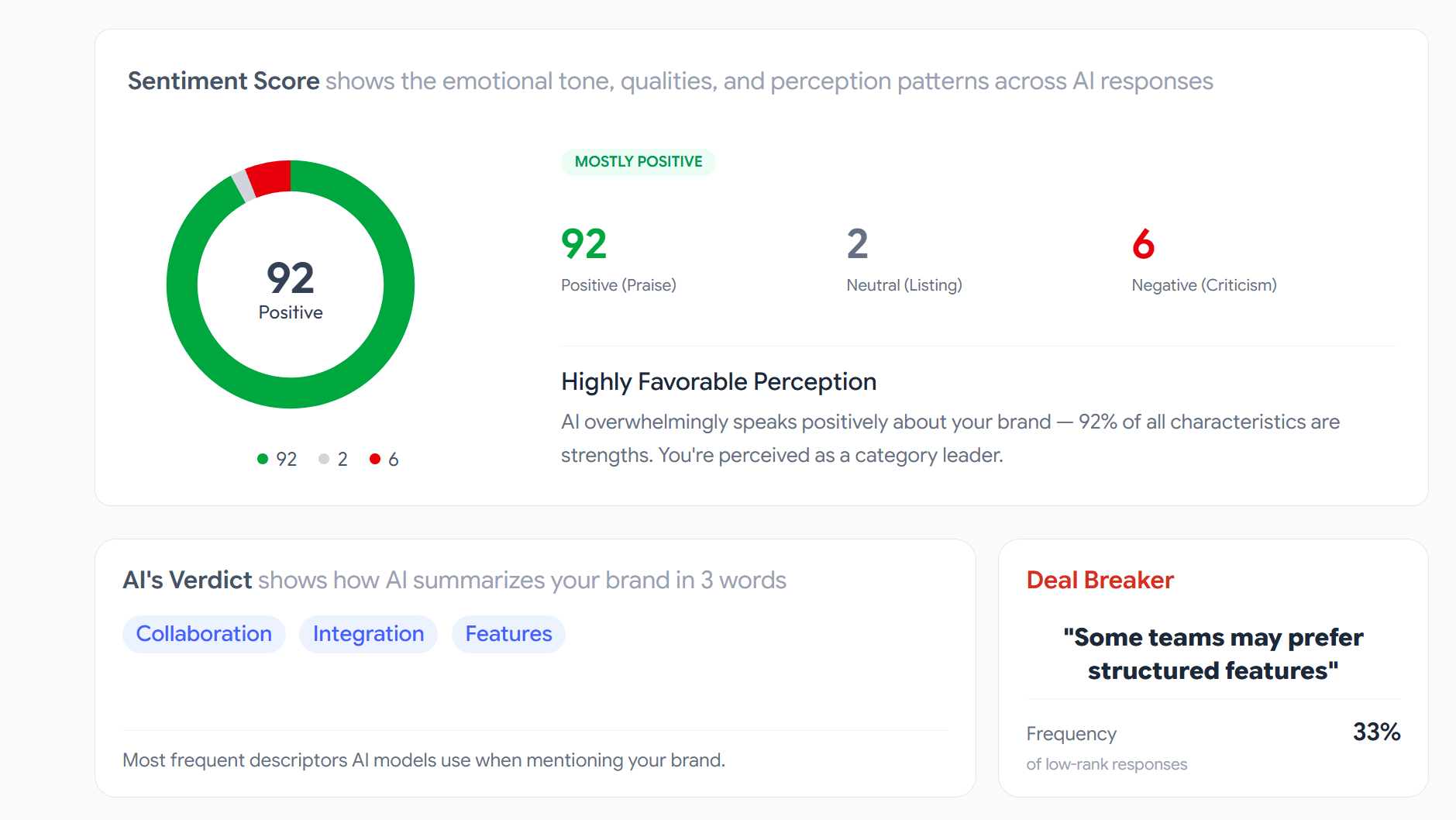
When the model operates in thinking mode (chain-of-thought reasoning), the process changes fundamentally. The model processes dozens of sources, builds argumentation, and produces structured output with reasoning for each position. This costs significantly more in tokens, but the output isn’t just a list of brands - it’s analysis: why Brand A ranks above Brand B, which sources influenced the decision, which specific characteristics determined the position.
From this reasoning, the most valuable signal is extracted: deal breakers. Specific phrases that the model uses repeatedly to explain why your brand ranks below competitors. “Limited features compared to alternatives.” “Lacks enterprise-grade security.” “No native integrations with major platforms.” A single phrase that determines your position across dozens of queries.
Strategy instead of a report
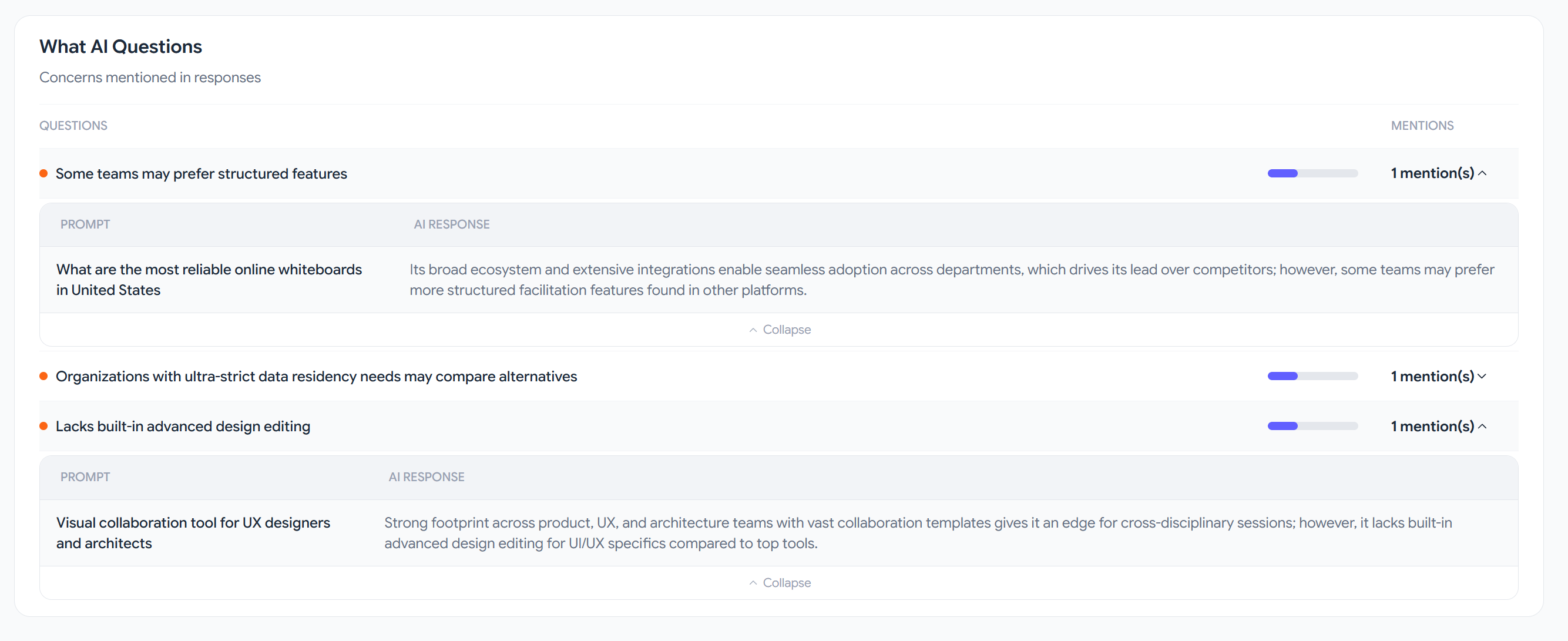
Identifying a deal breaker is half the work. The other half: tracing where it came from and providing a specific action plan.
A deal breaker like “limited features” might trace back to an old review on a review platform, an outdated article, and an inaccurate description on an aggregator. Three pieces of content, written at different times by different people, forming a single narrative that the model picks up and scales.
A second-generation tool doesn’t just surface this chain. It builds a strategy: what content to create, which platforms to publish on, which specific phrases to address. Not abstract “improve your visibility,” but concrete action items tied to specific deal breakers in specific models.
Multi-model tracking as an architectural decision
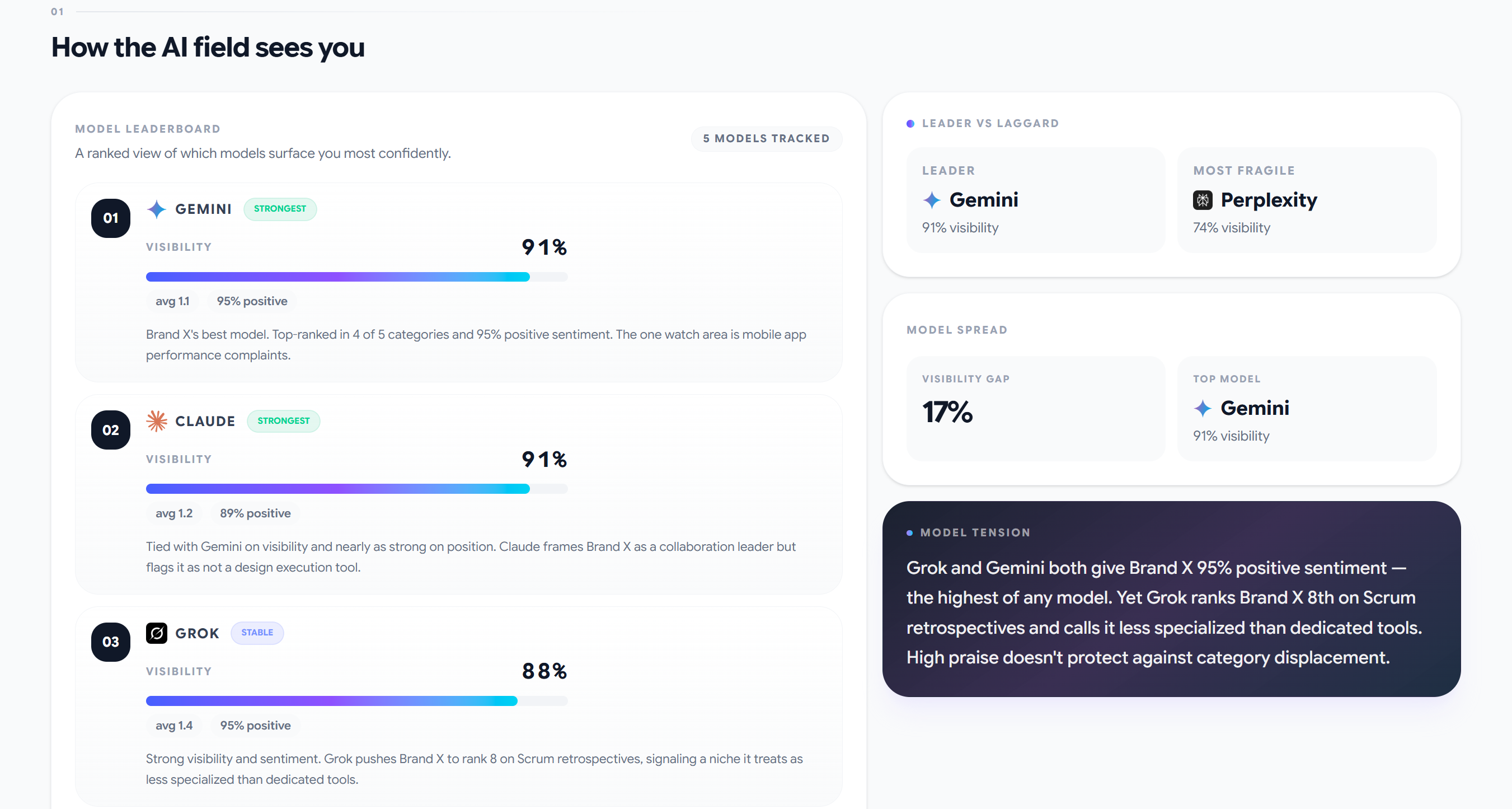
First-gen tools often focus on one or two models. Second-gen is built around a multi-model approach: ChatGPT, Claude, Gemini, Perplexity, Grok. Each model has its own retrieval architecture, its own sources, its own ranking patterns.
B2B buyers increasingly use Claude for deep analysis. Perplexity is becoming a primary tool for quick research. Grok is gaining traction among users focused on real-time data. Tracking a single model creates a blind spot that can hide a significant portion of your funnel.
The multi-model approach also reveals discrepancies: a brand can be #2 in ChatGPT and #8 in Gemini. These are different problems with different causes and different solutions. Without a multi-model view, you won’t know the second problem exists.
Query localization
AI models respond differently depending on query geolocation. For local businesses, this is a critical factor: results for a query from New York and from Austin can be completely different.
Second generation accounts for location: queries are tied to the specific geography of the business, and results reflect what real users see in that specific region.
Why the generational difference is architectural
You can’t just “add reasoning” to a monitoring tool. Thinking mode costs 3-5x more in API costs per query. It’s a different product economics model entirely.
First-gen tools are optimized for volume: more queries, more users, lower unit cost. Second-gen tools are optimized for depth: fewer queries, but each one provides a full breakdown with position, reasoning, and strategy.
This isn’t a matter of “better or worse.” It’s different architectural choices for different jobs. Monitoring answers “what’s happening.” Analytics answers “why, and what to do.”
For stakeholder reporting, monitoring may be enough. For a marketing team that wants to actively influence its brand’s position in AI recommendations, you need a tool that provides diagnostics and a plan.
Where the market is heading
Adobe reports that one in four buyers already uses AI as a primary product research tool. Ahrefs shows that 62% of citations in Google AI Overviews come from sources outside the traditional top 10. Authoritas found that even a #1 position on Google gives just a 33% chance of being cited in AI responses.
The AI channel is no longer experimental. It’s becoming part of the sales funnel. And measurement tools need to match that transition.
Mention monitoring was the right first step. It proved that AI visibility is measurable and meaningful. The next step is moving from observation to action. From “we were mentioned” to “we know our position, we know why, and we’re working on specific changes.”
When we designed Rankry, we built it as a second-generation tool from day one. Forced ranking with reasoning through thinking mode, multi-model tracking across five models, deal breaker analytics, strategic recommendations tied to specific sources. Not monitoring - a full cycle: measurement, diagnostics, strategy.
FAQ
Do I need to replace mention monitoring with positioning analytics? Not necessarily replace - more like supplement. Monitoring is useful for basic reporting and alerts. But if your goal is to actively improve your brand’s position in AI recommendations, monitoring alone isn’t enough. You need position data, ranking reasoning, and specific action items.
Why can’t I just query AI models manually and check the results? Language models are non-deterministic: the same query produces different answers on each run. For reliable data, you need multi-sampling - running the same query multiple times to establish a stable baseline position. Results also vary by geolocation, language, and phrasing. Doing this manually at scale is unrealistic.
Which AI models matter most to track? Depends on your audience. B2B buyers increasingly use ChatGPT and Claude for research. Consumer audiences lean toward ChatGPT and Perplexity. Grok is gaining traction among users focused on real-time data. Tracking a single model creates dependency risk: one update can shift your visibility overnight.