AI Share of Voice (AI SoV) is the percentage of AI-generated answers in your category that include your brand, measured against your competitors across a fixed set of buyer prompts. The formula is the one marketers already know, your appearances divided by all brand appearances, times 100. What changed is where you measure it: inside the synthesized answer an AI engine gives a buyer, not in a list of ten blue links.
It matters because the answer is now the destination. When someone asks ChatGPT or Perplexity for the best tool in your category, they read a short synthesized response and act on it. Either your brand is in that answer or it is not, and the average brand is mostly not: independent 2026 research puts the average brand mention rate across AI answers at roughly 17%, which means most companies are absent from the moment of decision and do not know it. This guide covers what AI SoV is, why a raw mention count misleads you, how to calculate it properly, how to benchmark against competitors, and how to move the number.
What AI Share of Voice is
AI Share of Voice measures how much of the AI conversation in your category belongs to you. Run a defined set of category prompts across the AI engines, count how often each brand appears, and your SoV is your share of that total.
Three properties make it different from the SoV marketers tracked in PR and advertising.
-
It is zero-sum. The answer space is finite. An AI response names a handful of brands, so when your share rises, someone else’s falls. Unlike impressions, you cannot buy more room, and as engines consolidate around fewer trusted sources, every point you gain is a point taken from a competitor.
-
It is probabilistic. The same prompt can return different answers on different runs, because models constantly reassess which sources they trust. A single snapshot is noise. SoV is only meaningful as a rate measured across many prompts and repeated over time.
-
It is buyer-journey-relevant, not backward-looking. Traditional SoV asked “how much coverage did we get last month?” AI SoV asks “when a buyer asks AI what to buy right now, how often do we show up?” That collapses the old awareness funnel into a single measurable moment.
Why a raw mention count lies
The instinct is to count mentions and call it done. That number will mislead you in four specific ways, which is why mature SoV separates into layers rather than one figure.
First, mention is not recommendation. An engine can name you in passing while recommending a competitor in the same answer. Counting both as equal hides whether you are the pick or the also-ran, a distinction worth its own treatment in why a mention is not a recommendation.
Second, position is invisible in a flat count. Being named first carries far more weight than being named fifth, but a raw mention tally scores them identically. This is why position-weighted SoV exists: it credits being the lead recommendation over being a footnote.
Third, sentiment is missing. Being mentioned as the budget compromise and being mentioned as the category leader are both “mentions,” yet they do opposite things to a buyer. A brand mentioned often but described poorly is not winning.
Fourth, the engines disagree, so a blended single number hides the truth. A brand can hold 40% SoV on one engine and 5% on another, because ChatGPT, Perplexity, Gemini, Claude, and Grok use different retrieval and different sources. One average buries which engine is ignoring you.
The fix is to track three variants together: citation SoV (is your site used as a source?), mention SoV (does your name appear in the answer?), and recommendation SoV (does the engine actually suggest you?). They answer different questions, and the gaps between them are where the strategy lives.
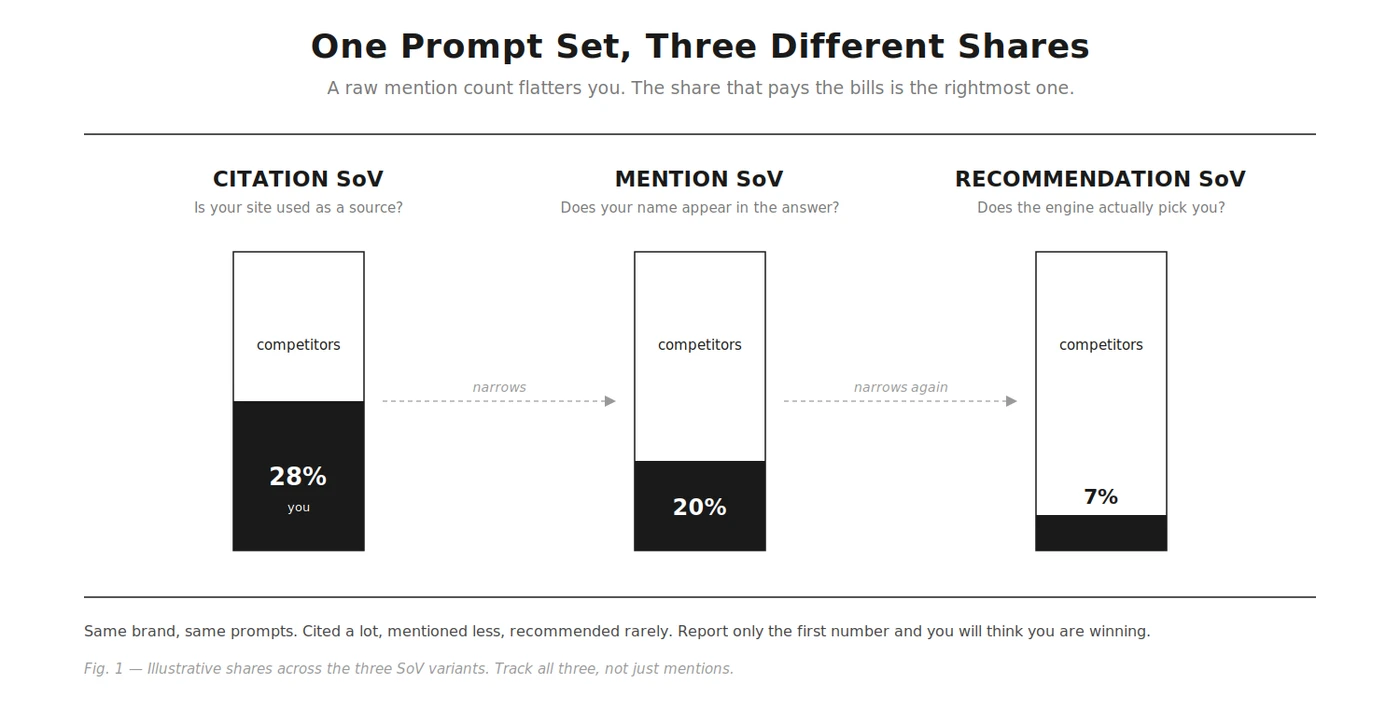
How to calculate AI Share of Voice
The core formula is simple:
AI Share of Voice = (your brand appearances / total brand appearances across the prompt set) x 100Worked example. You track 100 category prompts across five engines and five competitors. Across all those responses, brands are named 800 times total, and your brand is named 160 of them. Your mention-based AI SoV is 160 / 800 = 20%. Run the same counts for citations (your domain as a source) and recommendations (the engine suggests you) to get all three variants.
The steps:
-
Build the prompt set. This is the measurement, not a detail. A set of 30 to 50 prompts that mirror how buyers actually ask gives a usable baseline, and serious tracking runs more. Mix informational (“what is the best X for Y”), comparison (“X vs Y”), and recommendation (“recommend a tool for Z”) queries drawn from your real category, not your target keywords. The classic mistake is stuffing your brand name into the prompts (“why is BrandX the best”), which guarantees a flattering, meaningless score. Ask the questions a buyer who has never heard of you would ask.
-
Run every prompt across each engine separately. ChatGPT, Perplexity, Gemini, Claude, and Grok retrieve and recommend differently, so each is its own measurement. Run logged out to avoid your own history inflating the result.
-
Score each response at three levels: cited, mentioned, recommended. Record which brands appear at each level, and their position.
-
Divide and compare. Your appearances over total appearances, per engine and overall, per variant.
-
Sample and repeat. Because answers vary run to run, one pass is a guess. Re-run on a schedule so you are measuring a trend, not a coin flip.
For a single blended headline number, weight the engines by where your buyers actually are rather than averaging them flat. A B2B developer audience leans toward Claude and Perplexity; a consumer audience leans toward ChatGPT and Gemini. State the weighting openly whenever you report the blended figure, because an unstated formula is how two tools produce two different “share of voice” numbers for the same brand.
Benchmarking against competitors
AI SoV only means something next to your competitors, because it is zero-sum. A 20% share is strong in a field of ten brands and weak in a field of three.
Run the identical prompt set for three to five direct competitors using the same methodology, then line up the shares. The number that matters most is the delta between you and the category leader: it tells you exactly how much ground there is to take, and the zero-sum math tells you it has to come from someone specific.
Two views make this actionable. Per-engine SoV shows where you are weak, so you can see that you hold respectable share on one engine and near zero on another, which points at that engine’s preferred sources. And prompt-level SoV shows which questions you lose, since a brand can dominate “best X for enterprise” and be absent from “X alternatives,” and those gaps are direct content and citation assignments. This head-to-head and share-of-voice mapping across engines is what Rankry’s competitor tracking is built to automate, since doing it by hand across five engines and five competitors on a repeating schedule is the part that breaks down manually.
A realistic benchmark to anchor against: with the average brand mention rate sitting near 17%, breaking consistently above category average across your core prompts already puts you ahead of most competitors, and the leaders in any category pull dramatically higher.
Improving your Share of Voice
SoV rises when you win prompts you currently lose, which is a diagnosis-then-fix loop, not a single tactic.
-
Find the losing prompts. From your benchmark, list the specific prompts and engines where competitors appear and you do not. That is your target list, prioritized by how much real buyer demand each prompt represents.
-
Diagnose why you lose each one. Are you technically unreadable, unrecognized as an entity, missing from the sources the engine cites, or present but outranked? Each cause has a different fix, and the underlying mechanics of how engines choose brands are covered in what generative engine optimization is.
-
Apply the levers that move SoV. The ones that show up consistently across the research: earn third-party validation, because engines weight brands that other credible sources mention far above self-published claims; build a consistent, structured entity presence so the model recognizes you; create coverage breadth so you appear across the full range of category questions, not only your two best ones; and publish specific, data-backed content, since precise statistics get cited more than vague claims.
-
Mind the engine timing. Retrieval-based engines like Perplexity can reflect new content within days of indexing it. Training-based behavior in engines like ChatGPT and Claude shifts more slowly, as updates and third-party signals accumulate. Expect a few weeks before structural work shows up, and measure continuously so you can tie each movement back to the work that caused it.
AI Share of Voice is becoming the scoreboard for AI search the way rankings were for Google: a single comparable number that tells you how much of the answer you own, who owns the rest, and whether you are gaining or slipping. Measure it at the prompt level, per engine, across all three variants, and against named competitors. One flat mention count will tell you a comforting story. The full picture tells you where to fight.
Related Rankry resources
- Best AI Brand Monitoring Tools — track your share of AI mentions.
- AI Share of Voice — the definition and metrics.
- Competitor Tracking — head-to-head share of voice in Rankry.