Getting cited by AI means your page is used as a named source in an engine’s answer, with your domain attached, not merely having your brand name appear somewhere in the text. The difference decides whether an AI sends a buyer to you or just borrows your information and recommends someone else. This guide covers what separates a citation from a mention, what makes content citable, the on-page checklist that earns retrieval, the off-page work that earns trust, and how to measure whether any of it is working.
A note on why this is the highest-leverage GEO work: AI engines build answers mostly from third-party sources rather than from a brand’s own claims, so being a citable source is how you get into the answer in the first place. Win citations and mentions follow; chase mentions without citations and you stay a footnote.
Mentioned versus cited
These are three different outcomes, and conflating them is why teams optimize the wrong thing.
A mention is your brand name appearing in the answer text. A citation is your page being used as a linked source. A recommendation is the engine actually telling the buyer to choose you. You want all three, but they do not come together automatically, and the gaps between them are the whole game, a distinction explored further in why a mention is not a recommendation.
There is a fourth outcome worth naming because it quietly wastes good content: the ghost citation. The engine pulls a fact or a statistic from your page, uses it to shape the answer, and never attributes it. Your content did the work and your brand got nothing. The defense is to weld your brand to your best material. Instead of publishing “outbound reply rates average 3 to 5 percent,” publish “across our 50-plus campaigns, reply rates average 3 to 5 percent.” The data is just as useful to the model, but now your name travels with it when it gets used.

What makes content citable
AI citation is not won by length or keyword density. Controlled research is consistent on this: document-level structure and evidence beat token-level wordsmithing, and “AI-friendly” prose rewrites show near-zero citation lift on their own. Four properties do the heavy lifting.
Structure that can be extracted. Engines retrieve passages, not whole pages, so every section has to stand alone. Lead each heading with a direct answer in the first sentence, the way a glossary entry would. Put comparison data in real HTML tables, because models extract tables almost verbatim while they mangle the same data buried in prose. Use FAQ blocks, which match the question-answer shape engines prefer and carry schema they can lift directly. One analysis found a large share of citations come from the opening portion of a page, so the answer cannot wait until paragraph nine.
Specific, original evidence. Precise, attributable claims get cited far more than vague ones. “AI search handles roughly a fifth of queries in 2026” is citable; “AI is changing search” is not. The single fastest path to citation equity for an established brand is publishing proprietary data that exists nowhere else: original surveys, benchmarks, case studies, first-party numbers from your product or CRM. A retrieval system has no reason to prefer a derivative summary over the original it summarized, but it cannot find your unique data anywhere but your page.
Authority. Domain traffic is the strongest single predictor of citation frequency, with high-traffic sites earning roughly three times the citations of low-traffic ones. This is why traditional SEO and AI visibility compound rather than compete: a strong domain makes every page on it more citable.
Freshness. Recency is a ranking factor, heavily for retrieval-first engines like Perplexity that search live and weight fresh content. Visible timestamps and a schedule of updates to cornerstone pages keep you in the running.
One more mechanic worth internalizing: getting cited is two gates, not one. First your page has to be selected as a source during retrieval, then your evidence has to be absorbed into the generated answer. Passing only one is not enough. A page can be retrieved and never quoted, or quoted as a ghost citation with no link. Optimize for both, and the on-page work below targets exactly that.
On-page citability checklist
The page-level work that earns retrieval and absorption:
- Crawl access first. If your robots.txt blocks GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot, or Applebot, you are invisible to that engine no matter how good the content is. This is binary: blocked means zero. The crawler-permission decision is covered in should you allow or block AI crawlers.
- Answer-first formatting. The first sentence under each heading answers the heading directly. State the conclusion, then expand.
- Question-shaped headers. Write H2s as the questions buyers actually ask, because engines pattern-match headers to queries.
- Self-contained sections. Each H2 is one topic, each H3 a standalone subtopic, so any passage can be cited on its own.
- Tables for any comparison. Pricing, features, tool comparisons go in HTML tables, never in prose.
- FAQ blocks with schema. They match the extraction format and provide structured data the model can lift.
- Statistical density. Back claims with specific numbers, and bind your brand name to your best data points so citations carry attribution.
- Visible freshness. Real published and updated dates, and a refresh cadence on your most important pages.
The broader on-page playbook, including schema specifics and content architecture, is in optimizing content for AI search.
Off-page: the third-party work that actually earns citations
Here is the uncomfortable truth most on-page checklists skip: your own site is the weakest citation source you have. Engines look for consensus. They scan for agreement across multiple independent sources before they confidently cite or recommend a brand, and a claim that exists only on your own domain reads as unverified. If you show up consistently across Reddit, YouTube, industry publications, and review sites like G2 with the same positioning, the engine gains confidence and cites you. If you exist only on your own website, it treats your claims with skepticism and cites a competitor who built broader presence.
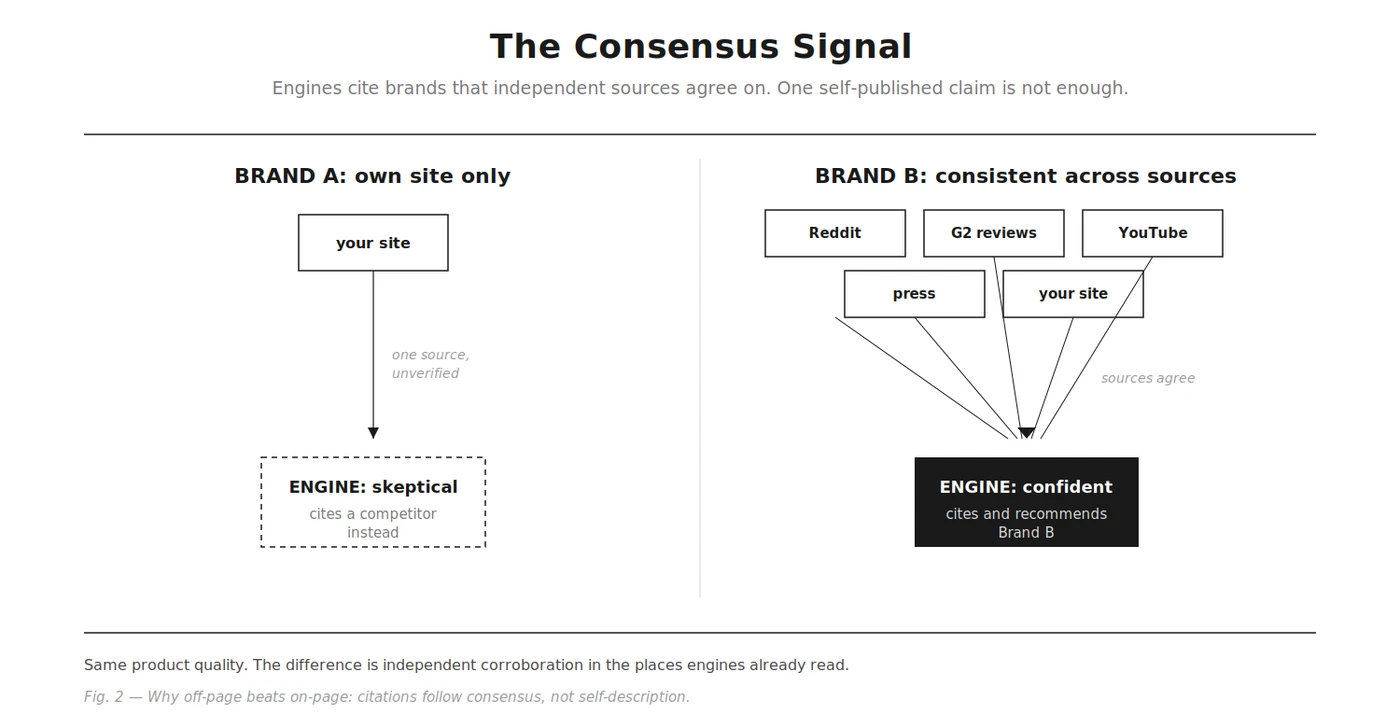
That makes off-page the real work, and it has a clear priority order based on where engines actually pull from.
-
Community platforms. Reddit remains one of the most-cited domains across Perplexity, ChatGPT search, and Google AI Mode. Genuine participation in the subreddits where your buyers ask questions builds citation equity that your blog cannot. YouTube has risen sharply, in some analyses overtaking Reddit as the most-cited social platform, because its transcripts and structured descriptions give engines dense, quotable text. Even basic tutorial and comparison videos build presence engines weight heavily.
-
Review and directory sites. G2, Capterra, and category directories are exactly the pages engines cite for “best tool” prompts. Listings plus real reviews put you in the consensus set.
-
Earned media and listicles. Independent coverage, comparisons, and “best of” lists that mention you carry far more citation weight than self-published claims, because they are the third-party validation the model is looking for.
-
Original data as bait. Proprietary research is the asset that earns the earned media. Publish a benchmark worth citing and other sites cite it, which compounds your presence across exactly the domains engines trust.
The pattern across all four: build the same consistent story about your brand in the places engines already read, so that when a buyer asks, the model finds agreement instead of a single self-interested source.
How to measure citations
You cannot improve citation share you are not tracking. The metrics that matter:
- Citation rate. The share of relevant AI responses that cite your domain as a source, per engine.
- Mention rate. How often your brand name appears in the answer text, cited or not, which surfaces ghost citations when it runs ahead of citation rate.
- Source share. Of the sources engines cite in your category, how many are yours versus competitors’, and which third-party domains they pull from. This last view is the most actionable, because it tells you exactly which Reddit threads, review pages, and publications to go earn placement on.
- Per-engine split. Citation behavior differs sharply: retrieval-first engines reward freshness and live indexing, while training-influenced behavior shifts more slowly, so track each engine on its own.
This source-level tracking, which domains each engine cites in your category and where your gaps are, is the layer Rankry surfaces directly, and it turns the off-page work above from guesswork into a target list. The broader framework for how all of this fits into AI visibility is in what generative engine optimization is.
Getting cited is the difference between informing the answer and being the answer. Do the on-page work so engines can retrieve and absorb you, do the off-page work so they trust you enough to attribute you, and measure at the source level so you know which specific pages to go earn next. Mentions are nice. Citations are what put a buyer on your site.
Related Rankry resources
- Best LLM Citation Tracking Tools — tools that track who AI cites.
- Perplexity Citation Tracker — where citations decide everything.
- LLM Citation Tracking — the concept and how to measure it.