Generative Engine Optimization (GEO) is the practice of structuring your content, brand signals, and technical setup so that AI engines like ChatGPT, Claude, Gemini, Perplexity, and Grok mention, cite, and recommend you when they answer buyers’ questions. Where SEO competes for a position on a results page, GEO competes for presence inside the answer itself.
The discipline exists because buying behavior moved. A growing share of buyers now ask an AI assistant for recommendations instead of scanning ten blue links, and the assistant replies with a short list, often three to five names, with reasoning attached. If you are not in that list, there is no page two to rescue you. This guide is the hub for everything we publish on the topic: what GEO is, how it differs from SEO and AEO, how generative engines actually choose which brands to name, the signal stack that decides whether you can be recommended at all, a practical workflow to improve, and how to measure it.
What is GEO, precisely
GEO is getting your brand selected and recommended inside AI-generated answers. The term traces to a 2023 research paper that tested how content changes affect visibility in generative engines and found that adding elements like citations, quotations, and statistics could lift a source’s visibility in answers by up to 40%. Since then it has grown from a research idea into a marketing discipline, and you will see it called AI visibility optimization, LLM SEO, AEO, LLMO, or AI search optimization. The names point at the same job.
That job has two halves, and most definitions stop at the first:
- Getting selected as a source. Your content is crawled, understood, retrieved, and cited when an engine assembles an answer in your category.
- Getting recommended as a brand. You are named, ranked well, and described accurately when buyers ask what to use.
These are related but not identical. An engine can cite your blog post and still recommend a competitor’s product in the same answer. Treating “we got cited” as the finish line is the most common GEO mistake, and the gap between being mentioned and being recommended is its own subject, covered in why a mention is not a recommendation.
GEO vs SEO vs AEO
The three overlap, and the work you have done for SEO is not wasted. But the target differs.
SEO optimizes for ranking. You want your page in the top positions of a results list, and the click happens on your site. The unit of success is a position and a visit.
AEO (Answer Engine Optimization) optimizes for extraction. Featured snippets, voice answers, and AI Overviews that lift a direct answer off your page. The unit of success is being the quoted answer to one specific question.
GEO optimizes for synthesis. Generative engines read many sources, reason over them, and compose an original answer. Your goal is to be in the engine’s working set and to come out of that synthesis named and recommended. The unit of success is presence and position inside a generated answer, often with no click at all.
Two practical differences follow. First, GEO is probabilistic: the same question asked twice can return different answers, so visibility is a rate you measure across runs, not a rank you check once. Second, GEO is multi-engine by nature. ChatGPT, Claude, Gemini, Perplexity, and Grok run different models, different retrieval, and different source preferences, and they disagree constantly. The full comparison is in GEO vs SEO: the key differences.
One reassuring overlap: AI engines lean on many of the same authority and relevance signals as traditional search, so a solid SEO foundation makes you easier to retrieve, interpret, and attribute. GEO reprioritizes that foundation rather than replacing it.
How generative engines pick sources and brands
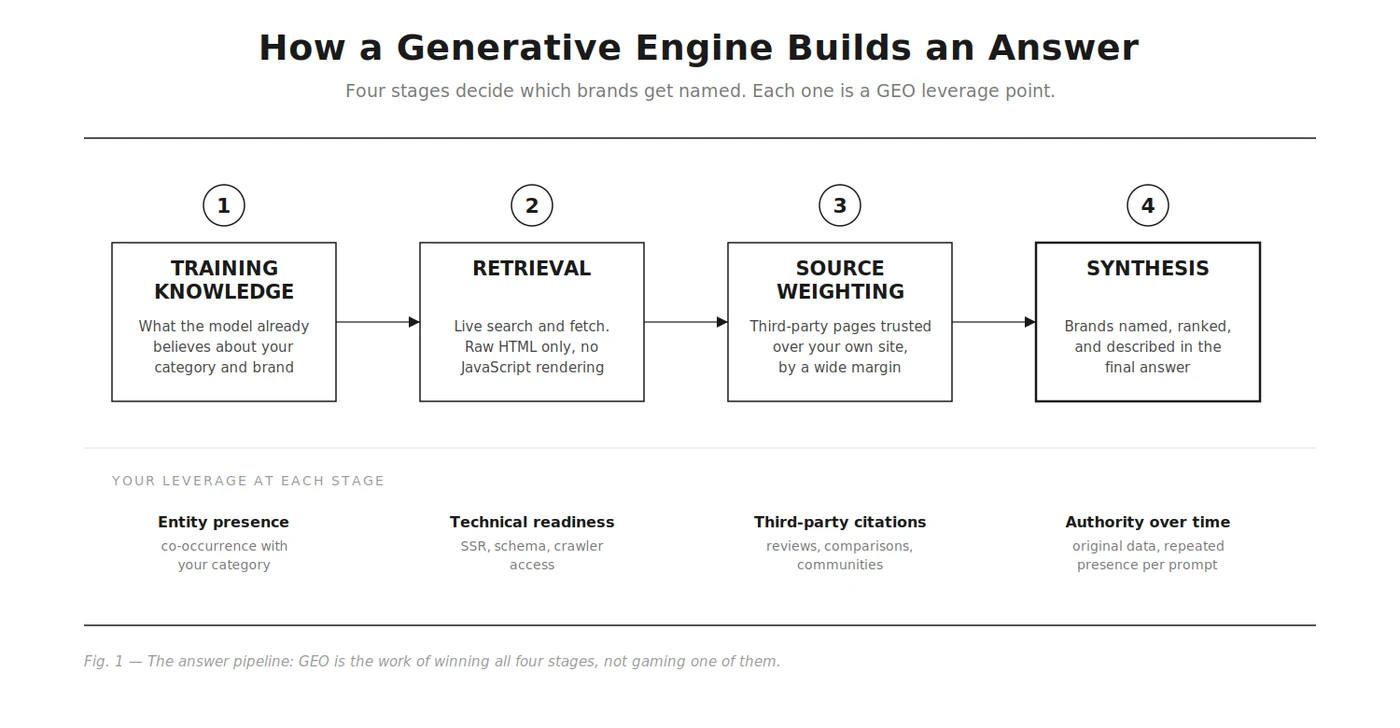
Understanding the selection mechanics tells you where the leverage is. When a buyer asks for a recommendation, several systems run in sequence.
-
Training knowledge. The model already holds an impression of your category from its training data: which brands exist, what they do, how they are discussed. Brands with weak entity presence in that data start invisible. Some engines lean on this heavily for recommendations, drawing on widely trusted reference sources and business directories.
-
Retrieval. For current questions, engines search the live web, often through their own indexes or partners, fetch pages, and read them. Technical readiness decides everything here: most AI crawlers read raw HTML only and do not execute JavaScript, so content they cannot fetch and parse does not exist for them. This is detailed in do AI crawlers read JavaScript, and your crawler permissions matter too, covered in should you allow or block AI crawlers.
-
Source weighting. Engines trust third parties over you. Their answers are built mostly from pages other than the recommended brand’s own site, with independent reviews, comparisons, and reference pages carrying more weight than self-published claims. Notably, ChatGPT’s search mode leans on Bing’s index, so a chunk of “ChatGPT optimization” is really Bing optimization.
-
Synthesis and ranking. The model composes the answer, choosing which brands to name, in what order, with what sentiment. Brand familiarity matters here: how often your name co-occurs with your category across the web is one of the strongest correlates of being recommended. The full breakdown is in how LLMs choose which brands to recommend.
The practical summary: GEO leverage sits in three places. What the model already believes about you, what the retrieval layer can read, and what third parties say where engines look.
The GEO signal stack
The signals are not a flat checklist, they stack. Each layer depends on the ones below it, which is why brands that skip ahead see nothing. We map AI visibility across five layers, and the pass rates fall off a cliff as you climb:
- Crawlability. Can AI systems fetch your site at all? Robots permissions, server access, no rendering traps. Roughly 85% of sites pass.
- Structured data. Can the engine understand what you are? Schema, clean architecture, answer-shaped content. Around 40% pass.
- Entity recognition. Does the model know you as a distinct brand rather than “some website in the category”? Consistent naming, entity profiles, category co-occurrence. Around 15%.
- Citations. Do third parties back up what you claim? Independent reviews, comparisons, mentions on the sources engines actually cite. Around 8%.
- Authority. Does the engine confidently put you in the top three when buyers ask? Single digits.
Read that funnel again: almost everyone can be read, almost nobody gets recommended. And you cannot skip layers. A citation campaign does nothing for a brand the model cannot recognize as an entity, because there is nowhere to attach the citation. The full framework with per-layer diagnostics is in the 5 layers of the AI visibility stack.
A practical GEO workflow
The work loops through three phases: measure, diagnose, fix. Then it repeats, because models update and competitors move.
-
Measure where you stand. Define the buyer questions that matter in your category (your prompt set), run them across all five engines, and record whether you are named, at what position, with what sentiment, and who wins instead. Do it blind (never name your own brand in the prompt) and logged out, or use tooling that runs clean sessions. The manual version of this method is in the AI visibility audit checklist.
-
Diagnose the gaps. For each prompt you lose, identify the layer. Is the site unreadable (layers 1-2), the brand unrecognized (layer 3), the cited sources missing you (layer 4), or are you present but outranked (layer 5)? Pull the sources engines cite in your category and list the ones where competitors appear and you do not.
-
Fix in priority order. Technical first: rendering, crawler access, schema, answer-shaped content, the on-page side of which is covered in optimizing content for AI search. Then entity: one consistent identity everywhere the model looks. Then citations: earn placement on the specific third-party sources engines already pull from, directories, comparison pages, reviews, and communities like Reddit, which several engines cite heavily. Then authority: original data, expert content, and the slow compounding of being the answer repeatedly.
-
Re-measure on a schedule. Visibility drifts as models retrain and indexes refresh. Cadence depends on how fast your category moves, weighed in daily vs weekly LLM monitoring.
A note on content, since it is where most GEO effort goes: lead every page with a direct, extractable answer to the question in the heading, write headers as the questions buyers actually ask, and back claims with specific data, because precise statistics get cited far more than vague statements. Category-definition pages like this one are among the highest-leverage GEO investments, since the brand that owns a category’s definition tends to get cited whenever the category comes up.
How to measure GEO
Because answers vary run to run and engine to engine, GEO measurement is statistical. The core metrics worth tracking:
- Visibility rate. The share of responses across your prompt set that mention you at all, per engine and overall.
- Position. Where you rank when named, since “mentioned fifth” and “recommended first” are different businesses.
- Sentiment. How the engine describes you, including the specific objections that block a recommendation.
- Share of voice. Your mention count against each competitor on the same prompts.
- Citation share. How often your domain, and the third-party pages that mention you, appear among cited sources.
- Consistency. How stable all of the above is across engines, runs, and weeks.
Two measurement traps to avoid. Do not collapse everything into one number: a single visibility score hides which prompts you lose, which engines ignore you, and whether you are climbing or sliding. And do not confuse referral traffic with visibility, since most AI exposure produces no click, a topic covered in AI referral traffic and how to track it. In Rankry we track 23 metrics across these dimensions, but the principle matters more than the count: measure at the prompt level, per model, over time, and tie every fix you ship to the specific prompts it was meant to move. The broader case for why this measurement matters is in why AI visibility matters.
GEO in 2026 is where SEO was in its early years: the channel is growing fast, most brands are invisible and do not know it, and the fundamentals reward whoever does the unglamorous work first. Start by measuring. Everything else follows from knowing exactly where you stand.
Related Rankry resources
- Best GEO Tools — compare generative engine optimization software.
- Generative Engine Optimization (GEO) — the glossary definition.
- AI Readiness Audit — the technical foundation of GEO.