Ask the same buyer question across the five major AI engines and you will get five different answers, with different brands named in a different order. This is not a glitch or an edge case. When researchers ran nearly 3,000 identical prompts across ChatGPT, Google AI, and Claude, the engines returned the same brand list less than 1% of the time. A separate analysis of 6.8 million AI citations found that only about 11% of cited domains appear across multiple platforms for identical queries. The engines are not slightly out of sync. They are running different playbooks.
That creates a problem most brands do not see coming: checking your visibility on one model tells you almost nothing about the other four. This guide explains why the models disagree, why betting on a single one is a real risk, how to track all five, and how to reduce the volatility once you can see it.
Same question, different answers
In the old search world, there was one Google. You ranked or you did not, and everyone saw roughly the same results page. AI search shattered that. A buyer can ask ChatGPT for the best tools in your category, ask Gemini to compare options, ask Claude to shortlist vendors, ask Perplexity to recommend a provider, and ask Grok the same thing, and each one runs its own private research session and composes its own answer.
The practical effect is that your brand can be the top recommendation on one engine and completely absent on another, for the exact same question. A founder checking ChatGPT might conclude they are doing fine. A buyer who happens to use Perplexity might never see them. Both experiences are real, and the gap between them is invisible unless you are looking at all five.
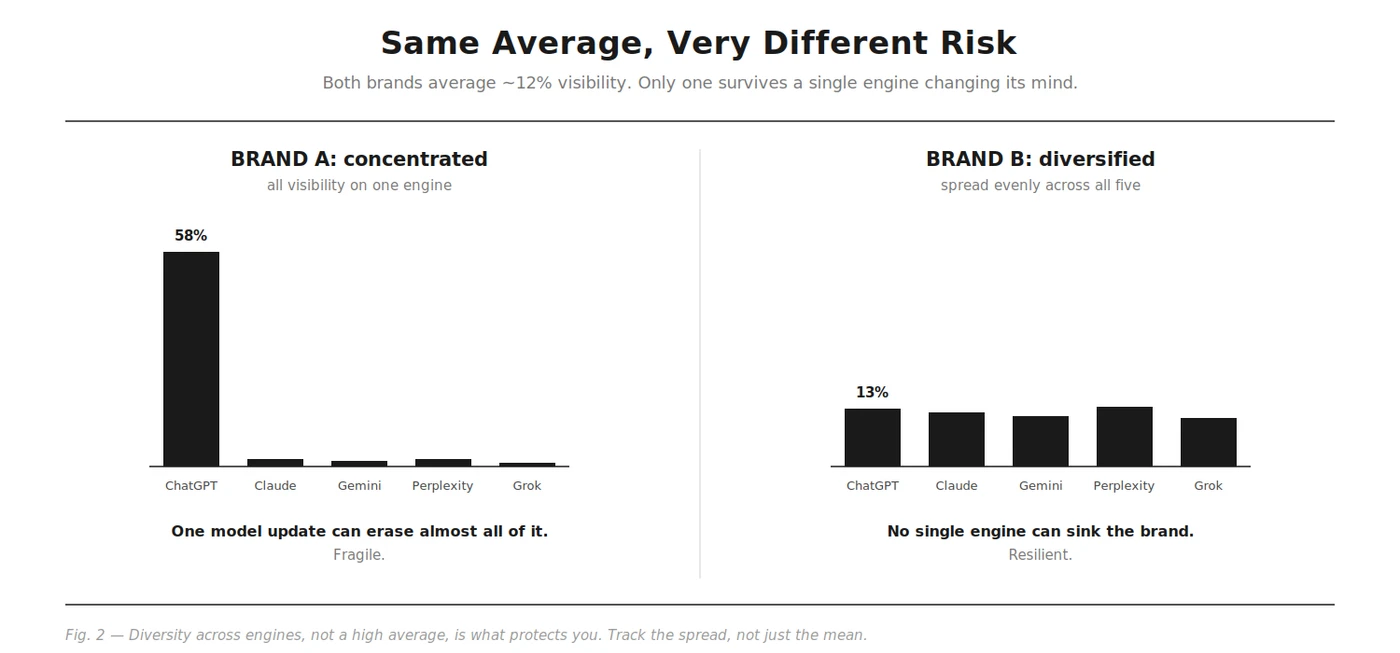
This is why a single visibility number lies. “We have 20% visibility” means nothing without “on which engine,” because the spread between engines is routinely larger than the number itself.
Why the models disagree
The disagreement is structural, not random. Four differences stack up.
Different indexes. Each engine reads a different slice of the web. ChatGPT’s search leans on Bing’s index, Gemini draws on Google’s index and Knowledge Graph, Claude has leaned on Brave’s index, and Perplexity built its own proprietary index of hundreds of billions of URLs. If your brand is strong in one index and thin in another, the engines built on them inherit that gap.
Different retrieval modes. Some engines answer primarily from training data, others search live for every query. ChatGPT often answers from its trained knowledge and only retrieves when it decides the question needs it. Perplexity searches the live web on every single query and weights freshness heavily. This means a brand new page can show up in Perplexity within days while taking far longer to influence training-based behavior in ChatGPT or Claude.
Different source preferences. Each engine trusts different places. Perplexity leans on community sources, with Reddit as a leading citation source, and on vertical directories. Gemini favors structured, verifiable data and the Knowledge Graph. ChatGPT prioritizes review signals from credible third-party platforms. Claude leans toward earned media and cautious, well-sourced claims. The same brand can clear one engine’s bar and fail another’s.
Different citation density and temperament. The engines do not even cite the same amount. Perplexity cites around 22 sources per answer on average, ChatGPT around 8, and some engines far fewer. A citation-dense engine gives more brands a chance to appear; a sparse one names only the few it is most confident about. Add the probabilistic nature of all of them, where the same prompt run twice can shift, and you get genuine variance on top of the structural differences.

The deeper takeaway: optimizing for one engine does not optimize for the others, because they reward different things. But underneath the differences they share one behavior, which is the good news in the next sections: all of them are consensus builders that surface brands corroborated across many independent sources. The mechanics of that shared logic are covered in how LLMs choose which brands to recommend.
The single-model dependency risk
Most brands, when they bother to check at all, check ChatGPT and stop. That is a concentrated bet on one engine, and the ground is moving under it. ChatGPT’s share of AI search has slid from the high eighties to the mid-sixties over the past year while Gemini surged from low single digits into the high teens. The audience is fragmenting across engines, not consolidating on one.
The risk has three parts.
You misjudge your real visibility. If you only check the one engine that happens to like you, you will think you are winning while a growing share of buyers using other engines never sees you.
You optimize for the wrong target. Pour all your effort into ChatGPT’s preferences and you may still be invisible on Gemini and Perplexity, which reward different signals. The work does not transfer automatically.
You are exposed to a single engine’s volatility. Engines update models, change retrieval, and shift source preferences on their own schedules. A brand concentrated on one engine can lose most of its AI visibility in a single model update it had no warning of. Spreading presence across engines is the same logic as not depending on one traffic channel.
Different engines also skew to different audiences: technical and research buyers lean on Claude and Perplexity, while consumer audiences lean on ChatGPT and Gemini. Knowing where your buyers actually are decides which engines you cannot afford to be absent from.
How to track across all five
Because the engines disagree, visibility has to be measured per engine, never blended into one figure that hides the spread. The method:
-
Use one prompt set across all five. Run the identical buyer questions through ChatGPT, Claude, Gemini, Perplexity, and Grok so the comparison is clean. The manual version of this, and why it has to be run logged out, is in the AI visibility audit checklist.
-
Record per engine, not in aggregate. For each prompt, log whether you appear, at what position, with what sentiment, on each engine separately. The whole point is to see where the engines diverge.
-
Sample over time. Because answers are probabilistic, one run per engine is a coin flip. Re-run on a schedule so you are measuring a stable rate, with cadence weighed in daily vs weekly LLM monitoring.
-
Watch your diversity, not just your average. The single most useful multi-model metric is how evenly you show up across engines. A brand at 30% on one engine and 0% on the other four is far more fragile than a brand at 12% across all five, even though a flat average might rank them similarly. This cross-engine coverage is exactly what Rankry’s diversity metric measures, because doing it by hand across five engines on a repeating schedule is the part that breaks down manually.
Reducing volatility
Once you can see the spread, the goal shifts from chasing one engine to building presence broad enough that no single engine’s quirks can sink you.
-
Fix the shared foundation first. Every engine has to be able to crawl, read, and parse your site, and all of them reward clear entity definition and answer-shaped content. This baseline lifts you everywhere at once and is the highest-return work.
-
Build consensus across independent sources. Since all five are consensus builders, presence on the third-party sources they collectively read, reviews, comparisons, community threads, and earned media, raises you across engines rather than one at a time. This is the durable way to reduce per-engine variance.
-
Then patch the per-engine gaps. With the foundation solid, target the specific engines where you are weak using what each rewards: freshness and community presence for Perplexity, structured data for Gemini, review signals for ChatGPT, well-sourced depth for Claude. Diagnose the gap before you spend, since the same fix does not move every engine.
-
Re-measure continuously. Engines change, so volatility is never fully eliminated, only managed. Tracking per engine over time is what turns a surprise model update from a silent loss into something you catch and respond to.
The multi-model reality is permanent: there is no single AI search to optimize for, and there will not be. The brands that win treat the five engines as five separate channels with a shared foundation, measure each one honestly instead of averaging the truth away, and build the cross-source presence that makes them hard to dislodge from any of them. The first step is simply to stop checking one engine and calling it visibility. How all of this fits the larger discipline is in what generative engine optimization is.
Related Rankry resources
- AI Platforms — per-model visibility tracking across every engine.
- ChatGPT Visibility and Claude Visibility — why the same prompt diverges by engine.
- Cross-Model Coverage — track where one engine leaves you out.